![[kor] GPU Enabled Jupyter Notebook Settings on AWS EC2](/assets/images/wiki/2022-02-22-gpu-jupyter/g5instance.png)
[kor] GPU Enabled Jupyter Notebook Settings on AWS EC2
서론
클라우드 환경에서 딥러닝 학습 작업을 시작한다면, 가장 먼저 고려해야 할 점은 클라우드 환경의 어떤 자원을 사용할 것인지, 어떤 플랫폼을 자원에 세팅할 것인지에 대한 부분입니다. 이번 글에서는 AWS 클라우드의 EC2 서비스를 사용하여 인스턴스를 생성하고, 해당 인스턴스에 Jupyter Notebook 환경을 설정하는 방법을 알려드립니다.
본론
1. AWS 클라우드에서 딥러닝 작업 시작하기
AWS 는 머신러닝, 딥러닝과 같은 인공지능 알고리즘의 개발을 위한 다양한 플랫폼을 제공하고 있습니다.가장 대표적으로 AWS SageMaker 서비스는 시스템 설정을 어려워하는 인공지능 알고리즘 개발자, 데이터 분석가를 위해서 손쉬운 개발 환경의 설정이 가능하도록 도와줍니다. 하지만 이번 글에서는 조금 더 전통적인 방식으로 AWS EC2 서비스를 사용하여 컴퓨터 자원에 해당하는 인스턴스를 직접 생성하고, 그 위에 데이터 분석 및 알고리즘 개발 환경을 설정하는 방법에 대해 알아보겠습니다. 이를 통해서 AWS SageMaker 등이 실제로 어떻게 작동하는지 원리 등을 더 잘 이해하고 사용 가능합니다. 뿐만 아니라 해당 서비스 등에서 인스턴스의 종류가 제한적으로 지원된다면, 이에 유연하게 대응하는 것 또한 가능합니다.
2. EC2 인스턴스 선택 및 비용 예상하기
EC2 환경에서 딥러닝 작업을 시작하기 위해서는, 먼저 어떤 종류의 인스턴스 타입을 선택할 지 결정이 필요합니다. 인스턴스 타입의 결정은 크게 성능, 비용의 두 가지 요소를 보고 결정하게 됩니다. 인스턴스의 성능은 우리가 실행하고자 하는 작업의 종류와 크기에 영향을 받고, 비용은 일반적으로 인스턴스의 성능에 비례하여 증가하게 됩니다. 하지만 AWS 에서 제공하는 인스턴스의 종류는 2022년 2월 현재 시점에서 약 500개가 있는데, 그 중에서도 딥러닝 학습을 가속화할 수 있는 GPU 인스턴스는 G타입, P타입, DL타입, F타입이 있으며, 일반적으로는 G 와 P 타입을 사용하게 됩니다. 이번 글에서는 2022년 2월 기준으로 가장 최신의 GPU 인스턴스인 G5 를 사용하여 간단한 CNN 모델의 학습 작업을 수행해 보겠습니다.
3. EC2 인스턴스 실행하기
인스턴스 타입을 결정했다면, 인스턴스를 실행하는 것 부터 시작해야 합니다. AWS Console 환경에서 g5.xlarge 인스턴스를 실행하는 과정은 다음과 같습니다.
-
AWS Console 에 접속 후, 메뉴에서 EC2 서비스를 클릭합니다. 이 때, 지역은 G5 인스턴스를 지원하는 곳으로 선택해야 하며, 여기에서는 Oregon 지역을 선택합니다
-
오른쪽 상단의 Launch Instance 버튼을 클릭하여 인스턴스를 실행시킵니다
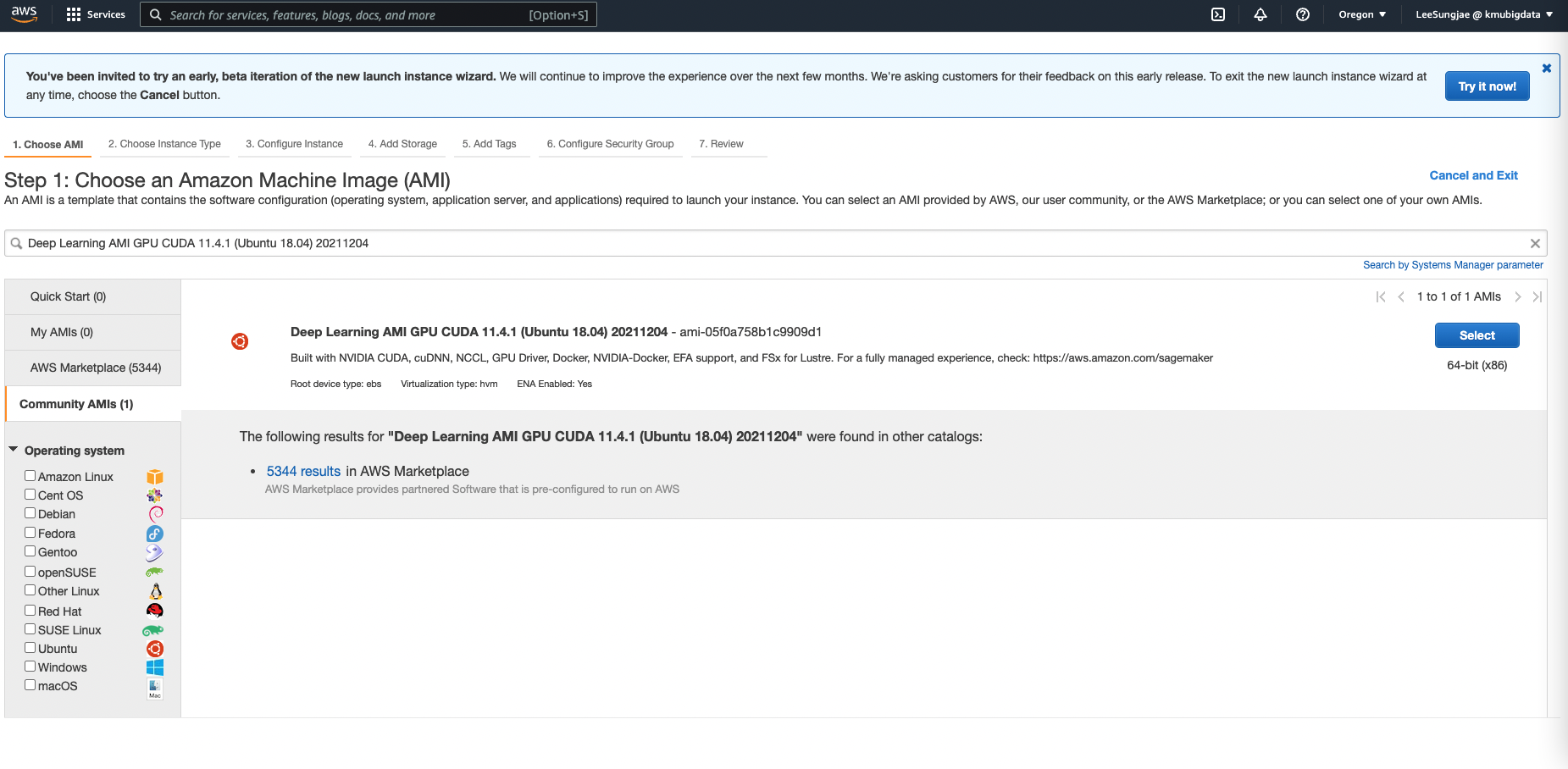
- 다양한 AMI 들 중에서, G5 인스턴스에 적합한 AMI 를 선택합니다. G5 는 CUDA 버전이 11.4 이상인 AMI 에서 정상적으로 작동하므로, ‘Deep Learning AMI GPU CUDA 11.4.1 (Ubuntu 18.04) 20211204’ 이름을 검색 후 Community AMI 에서 선택합니다
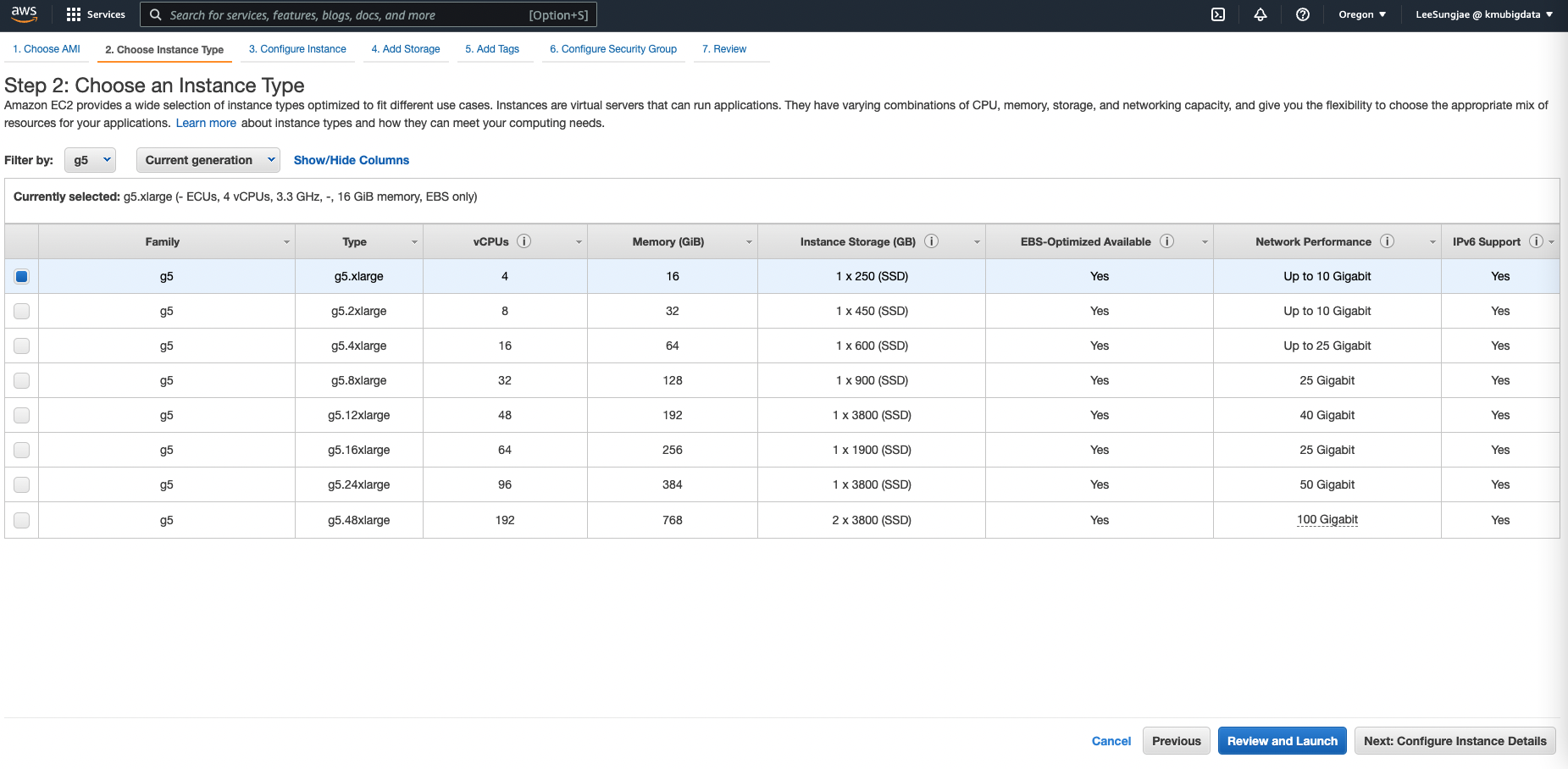
- 인스턴스 타입에서 g5.xlarge 를 선택하기 (G5 와 같은 최신 인스턴스는 Oregon 과 같이 인스턴스 지원이 빠른 지역에서만 선택 가능할 수 있습니다. 만약 인스턴스 타입이 보이지 않는다면, 해당 인스턴스가 지원되는 지역인지 다시 확인해 보세요)
- 다른 설정은 그대로 사용해도 큰 문제가 없지만, Security Group 의 경우에는 SSH 접속 뿐 아니라 Jupyter Server 접속을 위한 포트를 추가적으로 설정할 필요가 있습니다. 임의의 포트번호를 사용하면 되는데, 여기에서는 8800 을 사용합니다.
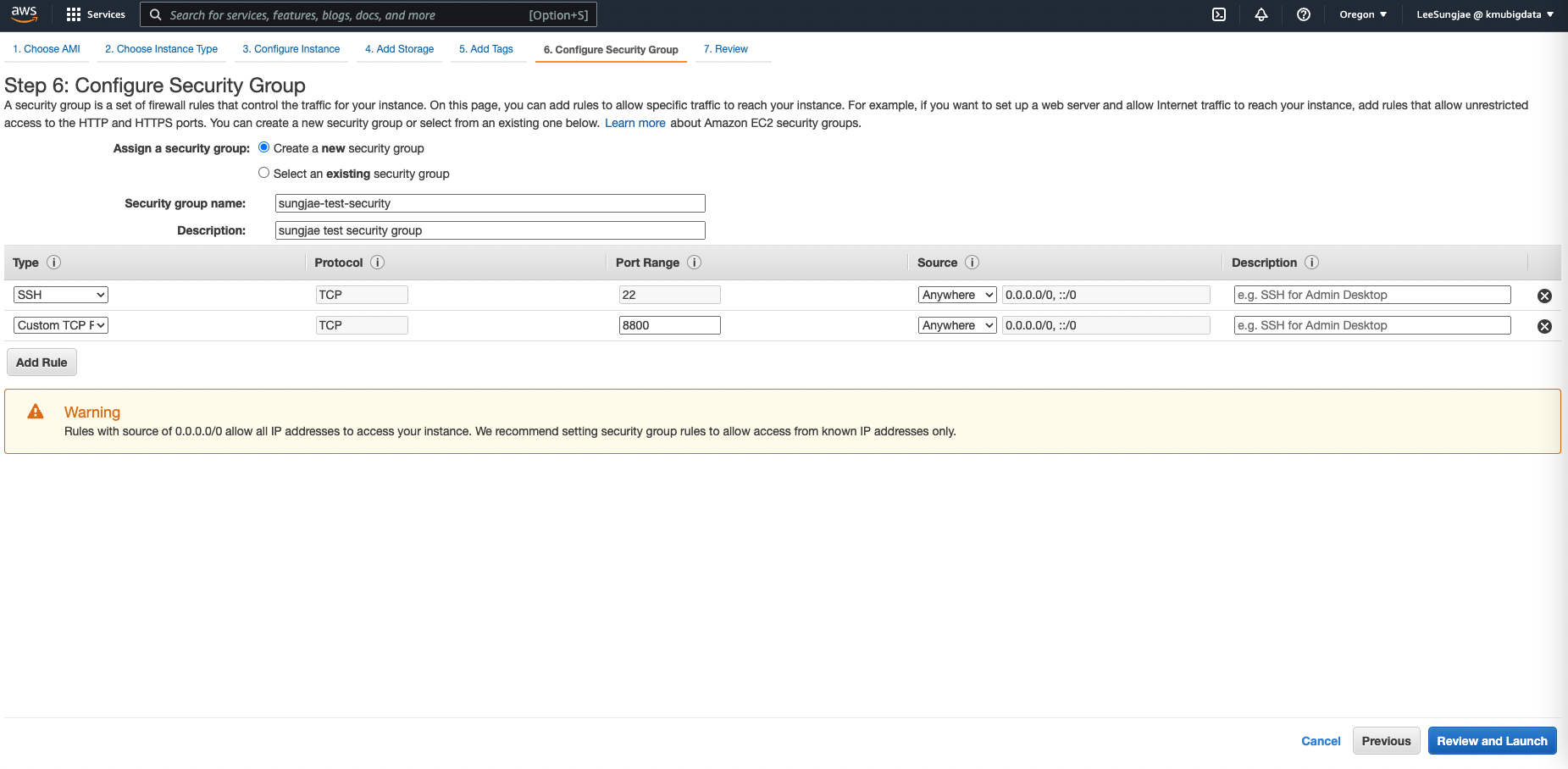
- 설정을 리뷰하고, 인스턴스를 실행합니다. 기존에 사용하던 키페어가 없다면, 새롭게 생성하여 다운로드 받습니다
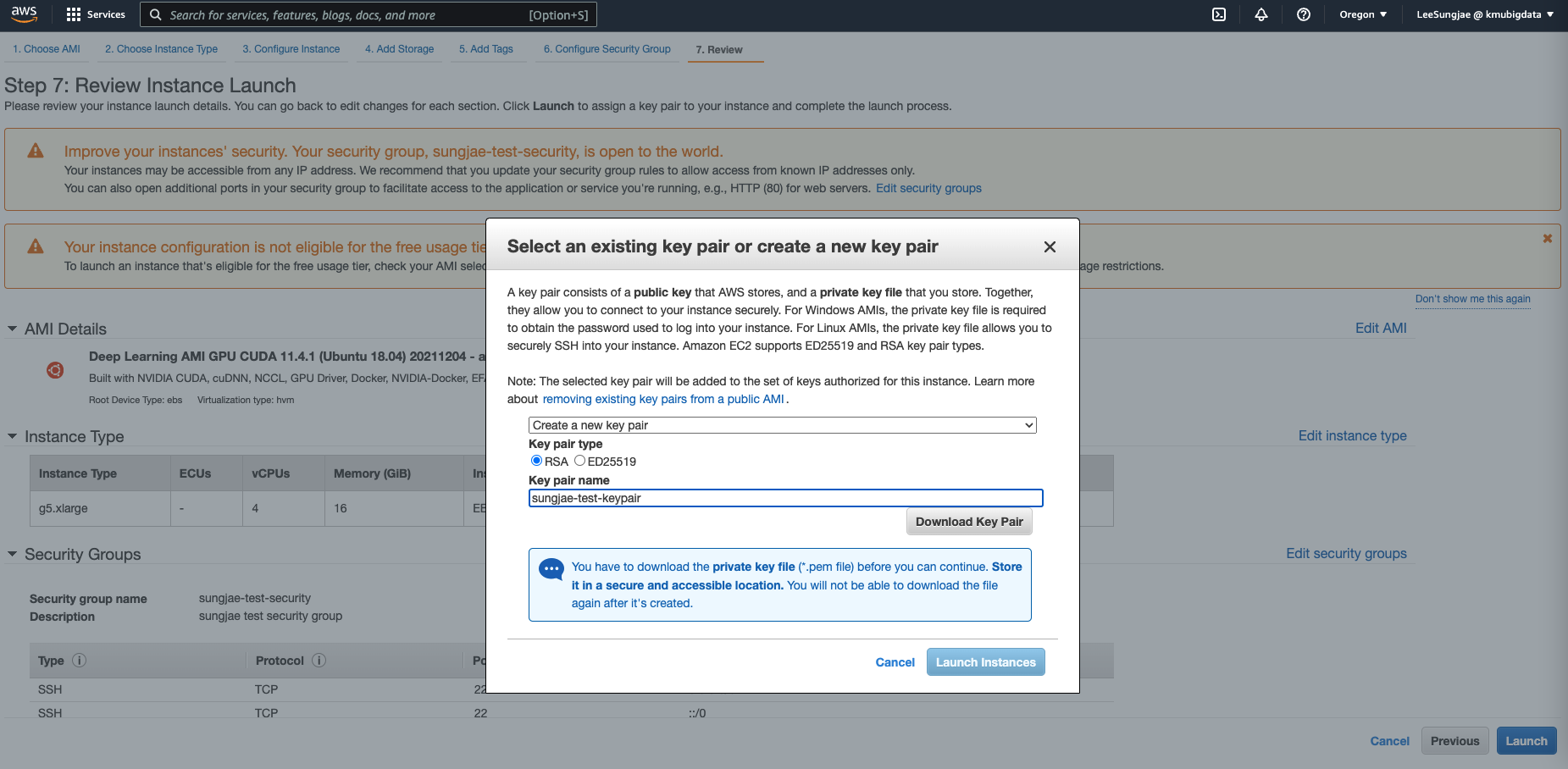
- 성공적으로 인스턴스 실행이 완료되었습니다. 다음으로는 인스턴스에 접속 및 Jupyter Server 세팅을 시작합니다.
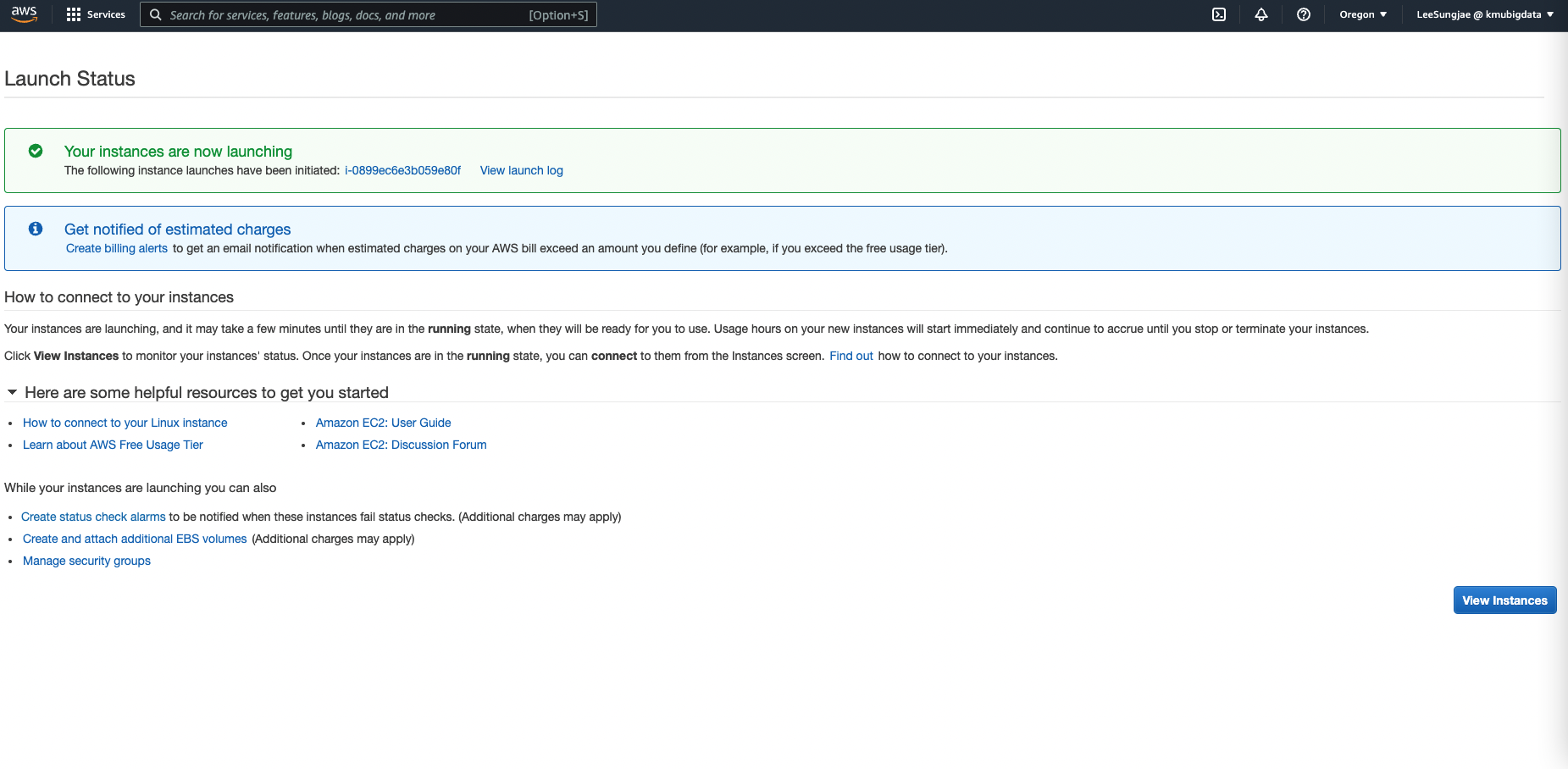
4. 인스턴스에 접속 및 Jupyter Server 세팅하기
위의 과정을 통해서 여러분은 작업을 실행할 수 있는, GPU 사용 가능한 컴퓨터 자원을 획득하게 되었습니다. 일반적으로 클라우드 컴퓨팅 자원을 사용하기 위해서, 개인이 가지고 있는 Local 컴퓨터 환경에서 클라우드 환경으로 SSH 접속을 진행하게 됩니다. SSH 접속 방법은 다음과 같습니다.
-
먼저 인스턴스가 정상적으로 실행중인지 확인합니다. Instance State 가 Running 이므로 접속을 시도해 봅니다. 해당 인스턴스를 선택 후, Connect 버튼을 클릭합니다.
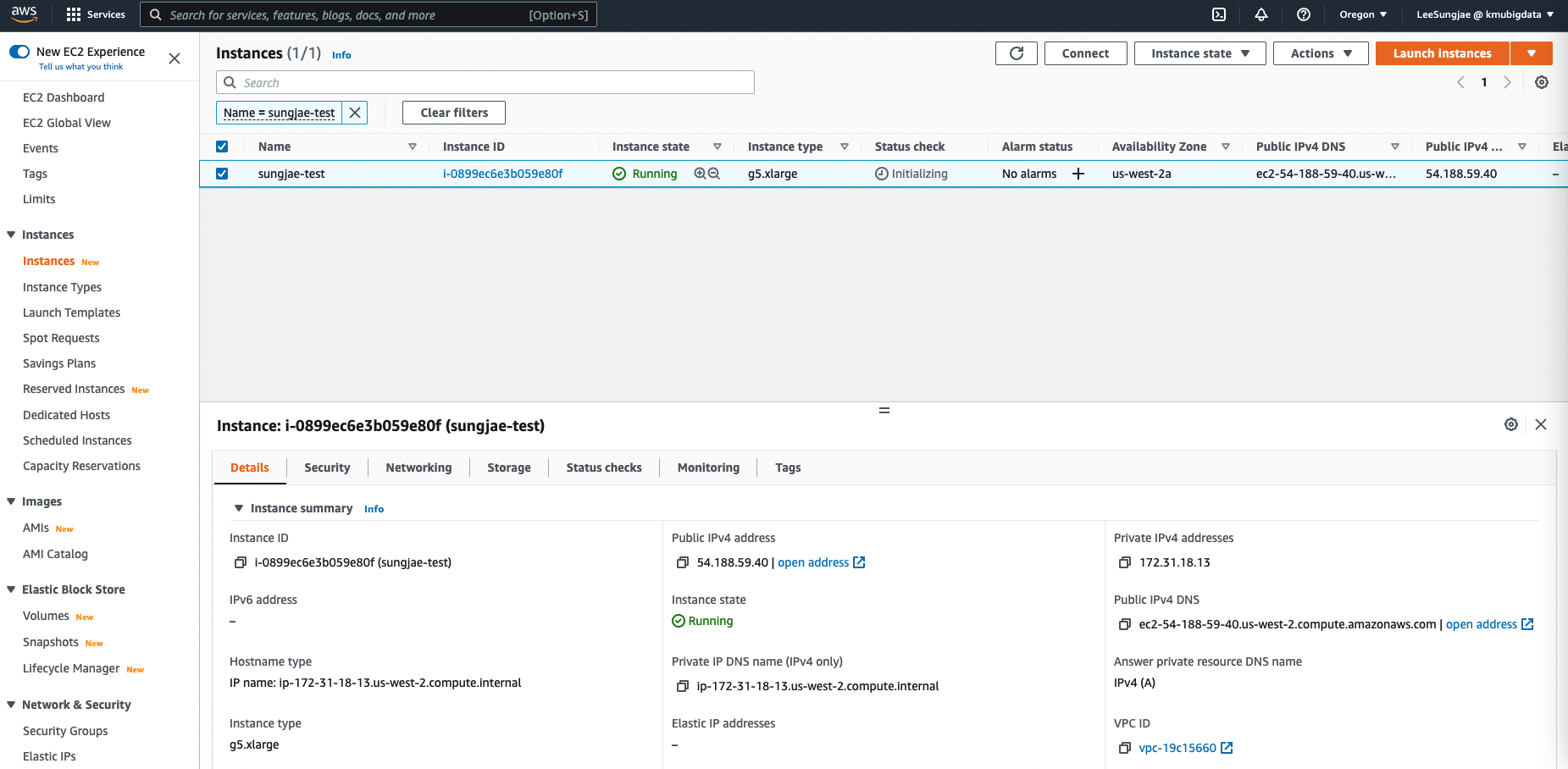
-
앞서 다운로드 받은 키페어 (sungjae-test-keypair.pem) 파일을 사용하여 명령어를 따라 SSH 접속을 진행합니다.
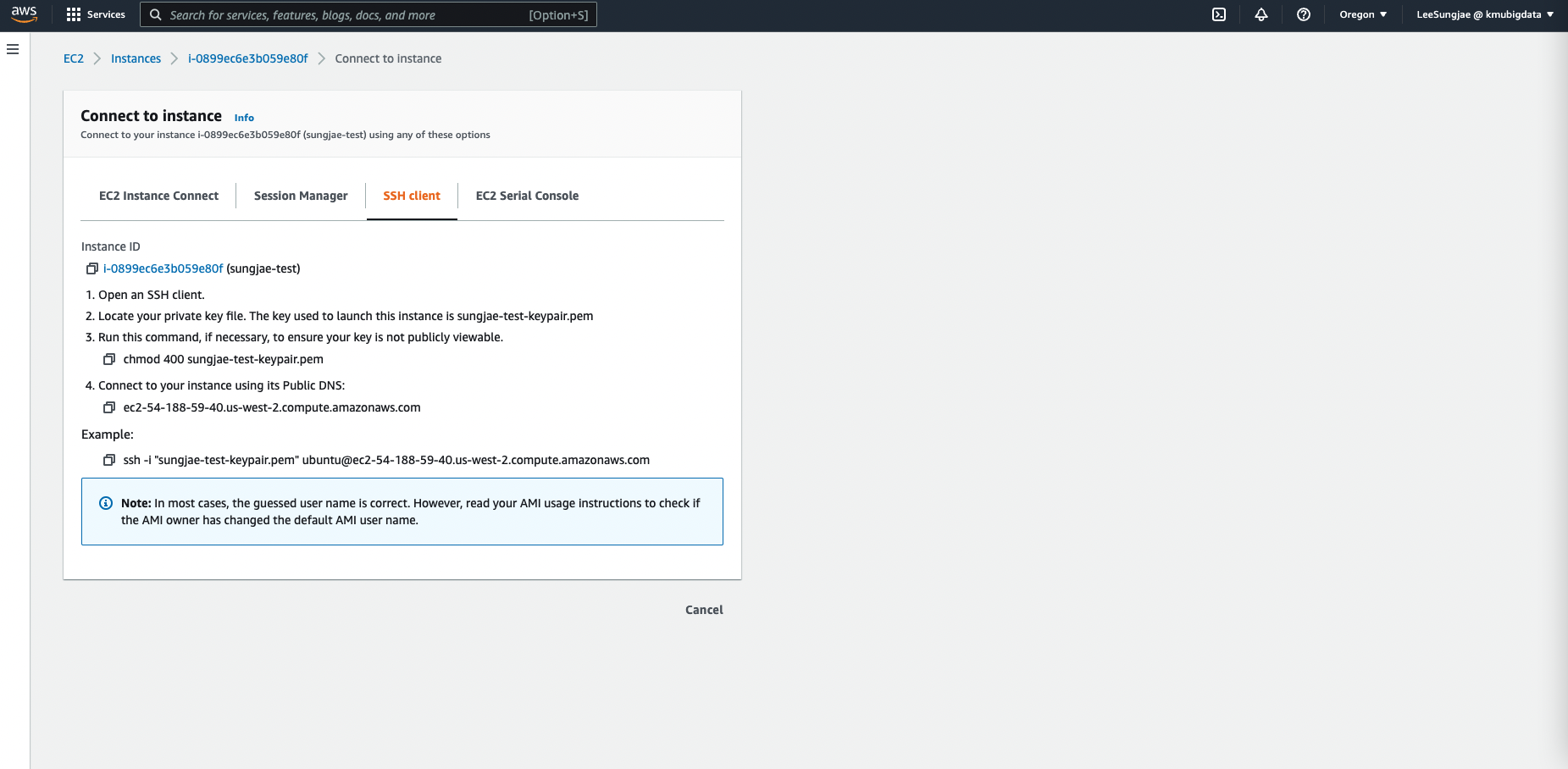
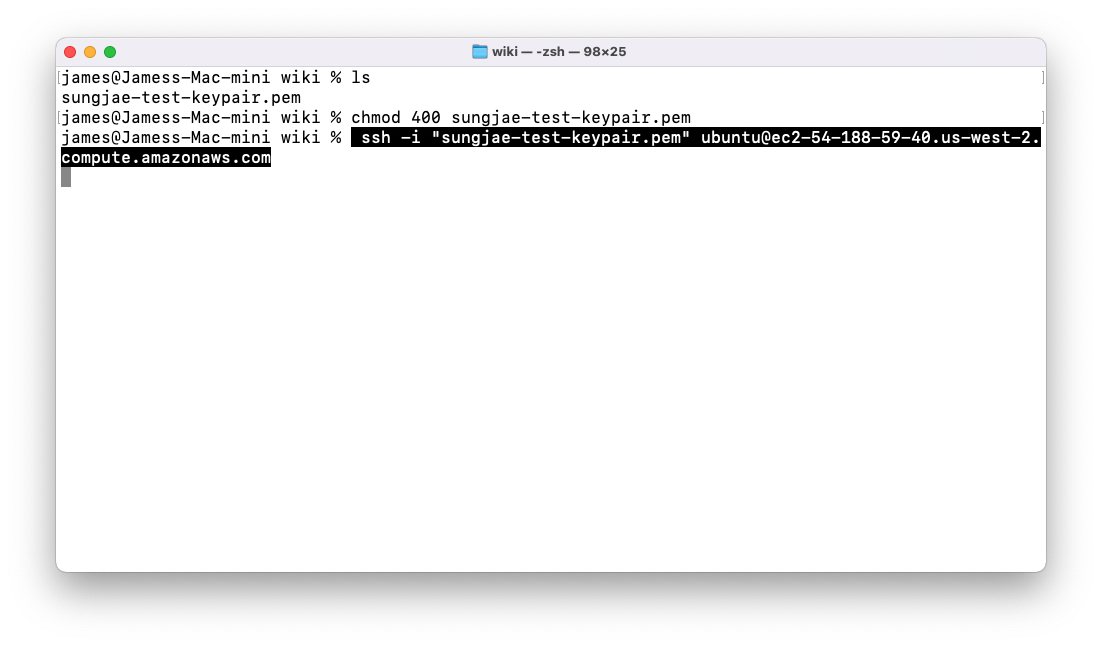
-
위와 같은 접속 화면이 나타났다면, nvidia-smi 명령어를 통해 GPU 정보를 확인해 봅니다
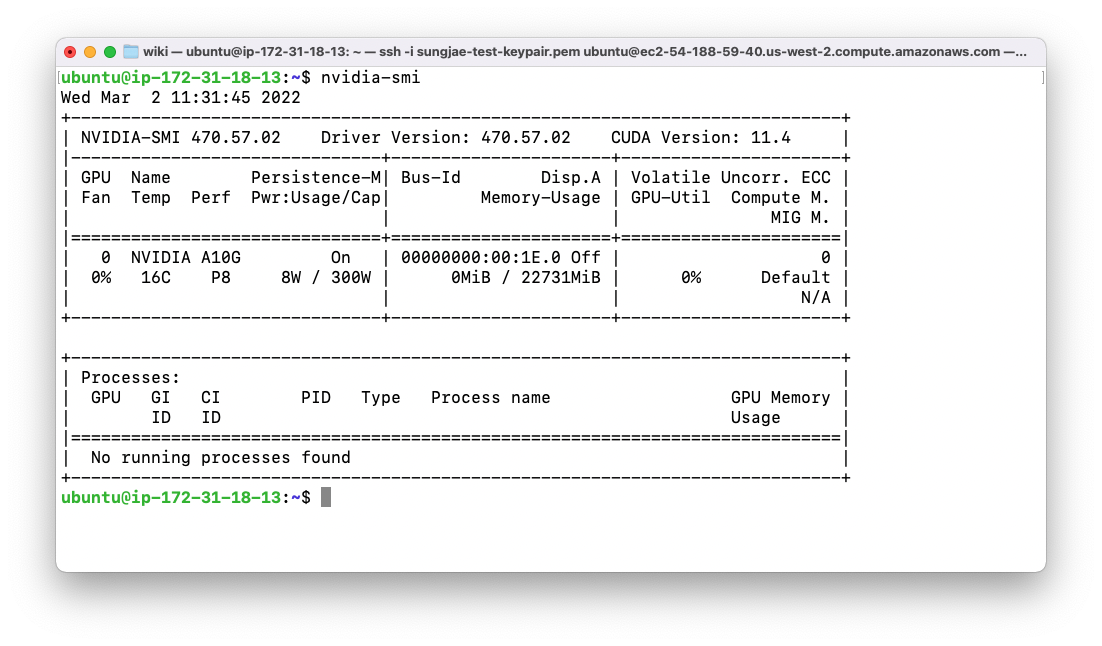
- 다음으로는 Docker 를 사용하여 Jupyter Server 의 이미지를 다운로드 받고, 실행시키는 과정을 설명합니다. 우선 아래의 명령어를 사용해 tensorflow 가 설치된 gpu-jupyter 이미지를 다운로드 받습니다
docker pull tensorflow/tensorflow:latest-gpu-jupyter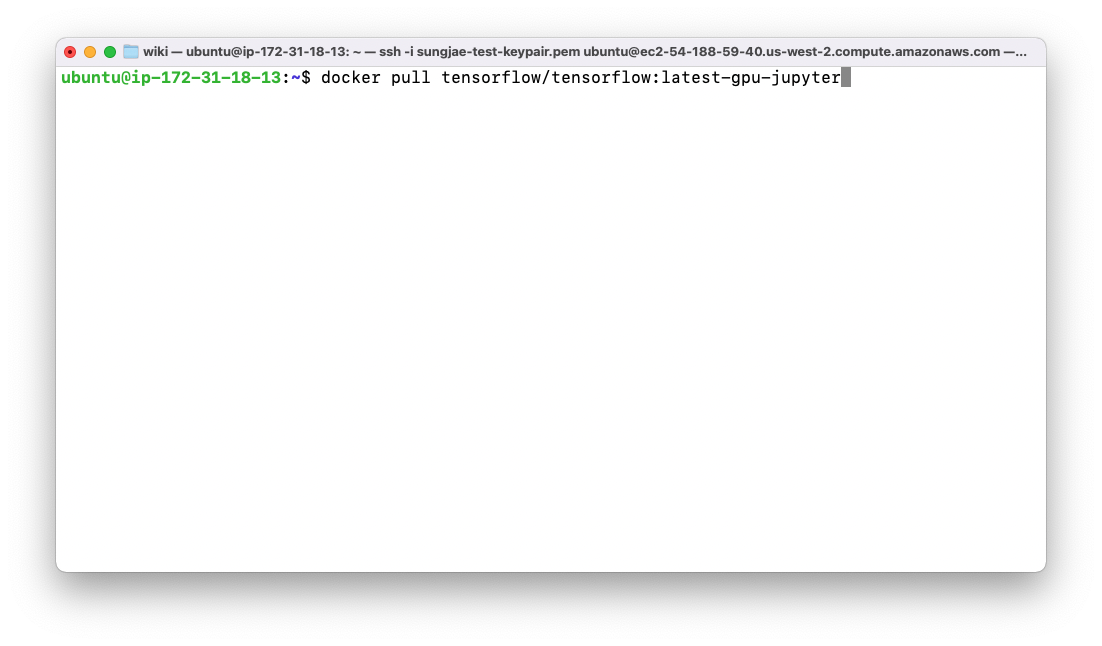
- 다음으로는 Jupyter 에 연결할 Directory 를 새롭게 생성합니다. 이를 통해서 Jupyter 의 파일 관리를 조금 더 자유롭게 할 수 있습니다. 생성 후에는 아래의 명령어를 사용해 Jupyter Server 를 실행합니다. 중요한 옵션의 명칭만 설명하면, 포트포워딩, 태그를 통한 네이밍, 볼륨 설정, GPU 사용 입니다. 각 옵션의 세부적인 사항은 docker documentation 을 검색해 옵션 부분을 살펴보세요
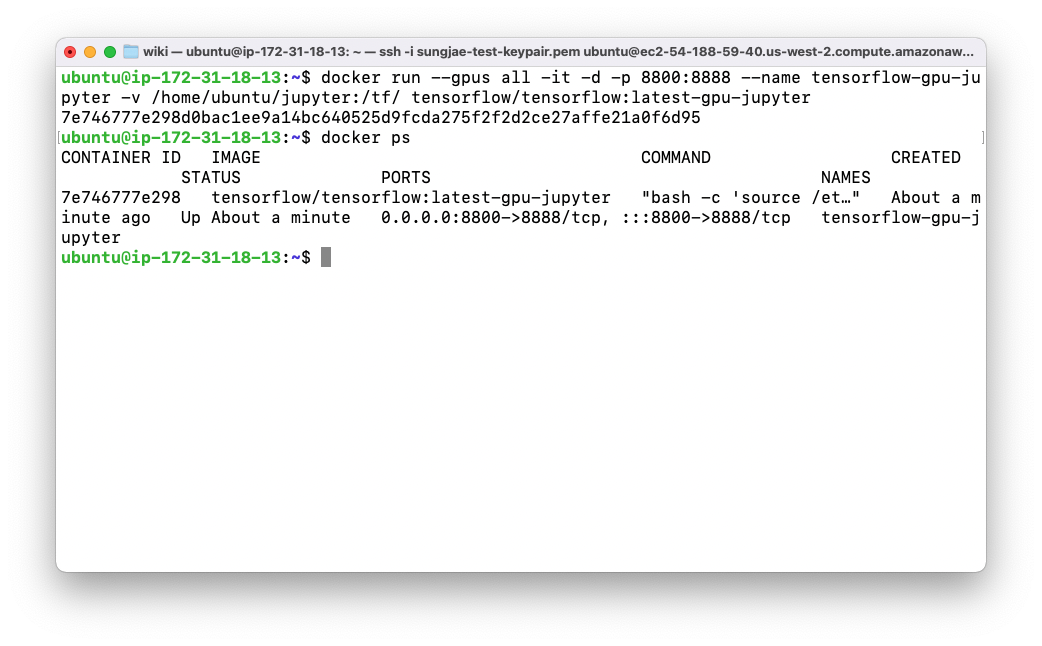
docker run --gpus all -it -d -p 8800:8888 --name tensorflow-gpu-jupyter -v /home/ubuntu/jupyter:/tf/ tensorflow/tensorflow:latest-gpu-jupyter
- 이제 우리가 실행한 인스턴스의 Public IP 주소에서, Jupyter Server 로 지정한 8800 포트번호에 접근하면 아래와 같은 화면이 보입니다. Token 을 알고 있어야 비밀번호 설정이 가능하므로, 아래의 명령어를 사용해 Token 을 알아냅니다. 세 개의 명령어를 차례로 작성하면 됩니다.
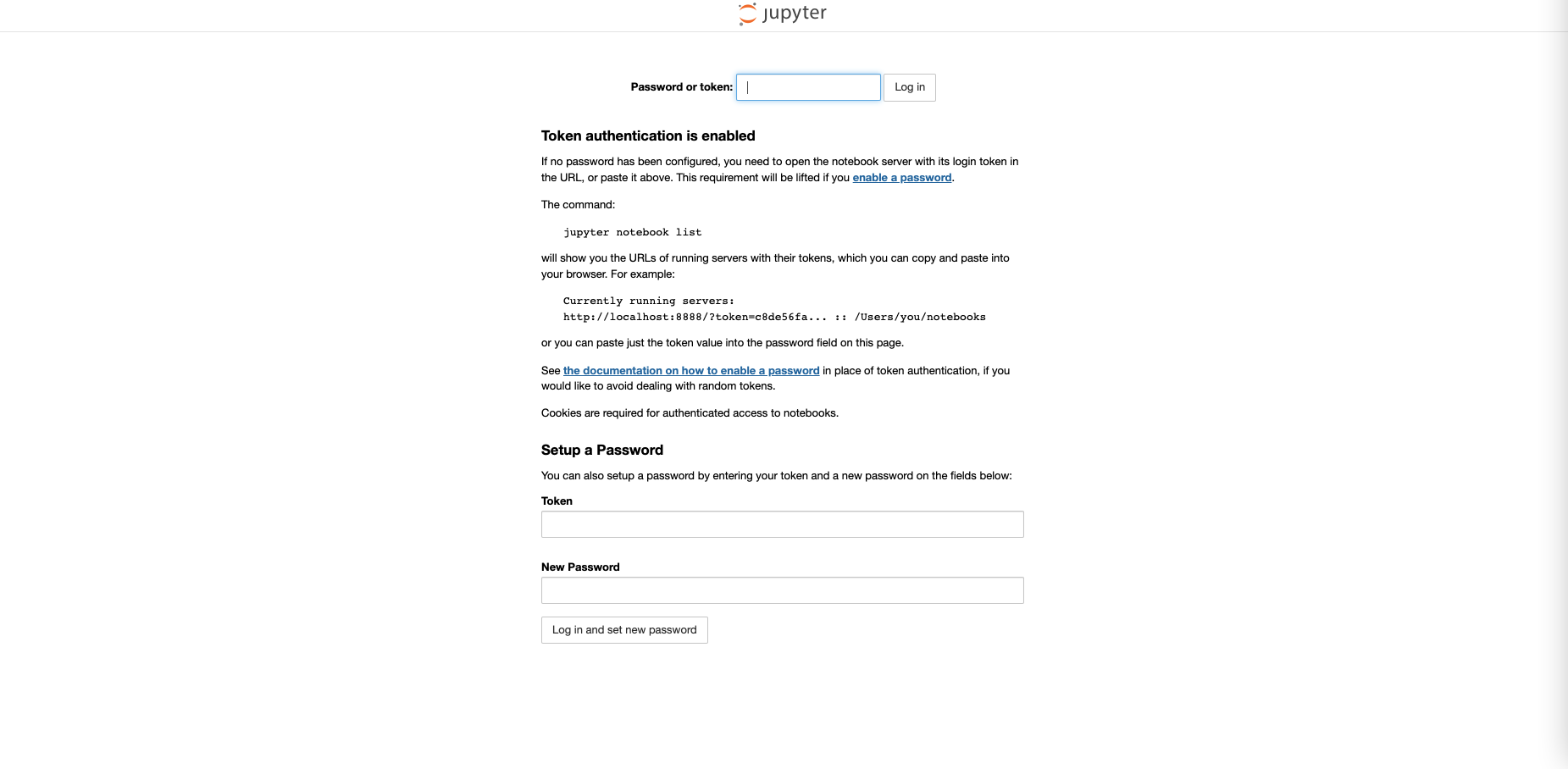
docker exec -it <container-id> /bin/bash ipython system("jupyter" "notebook" "list") - Token 을 사용해서 새롭게 비밀번호를 설정한 다음, 하나의 Jupyter Notebook 을 켜서 GPU Available 한지 테스트 합니다.
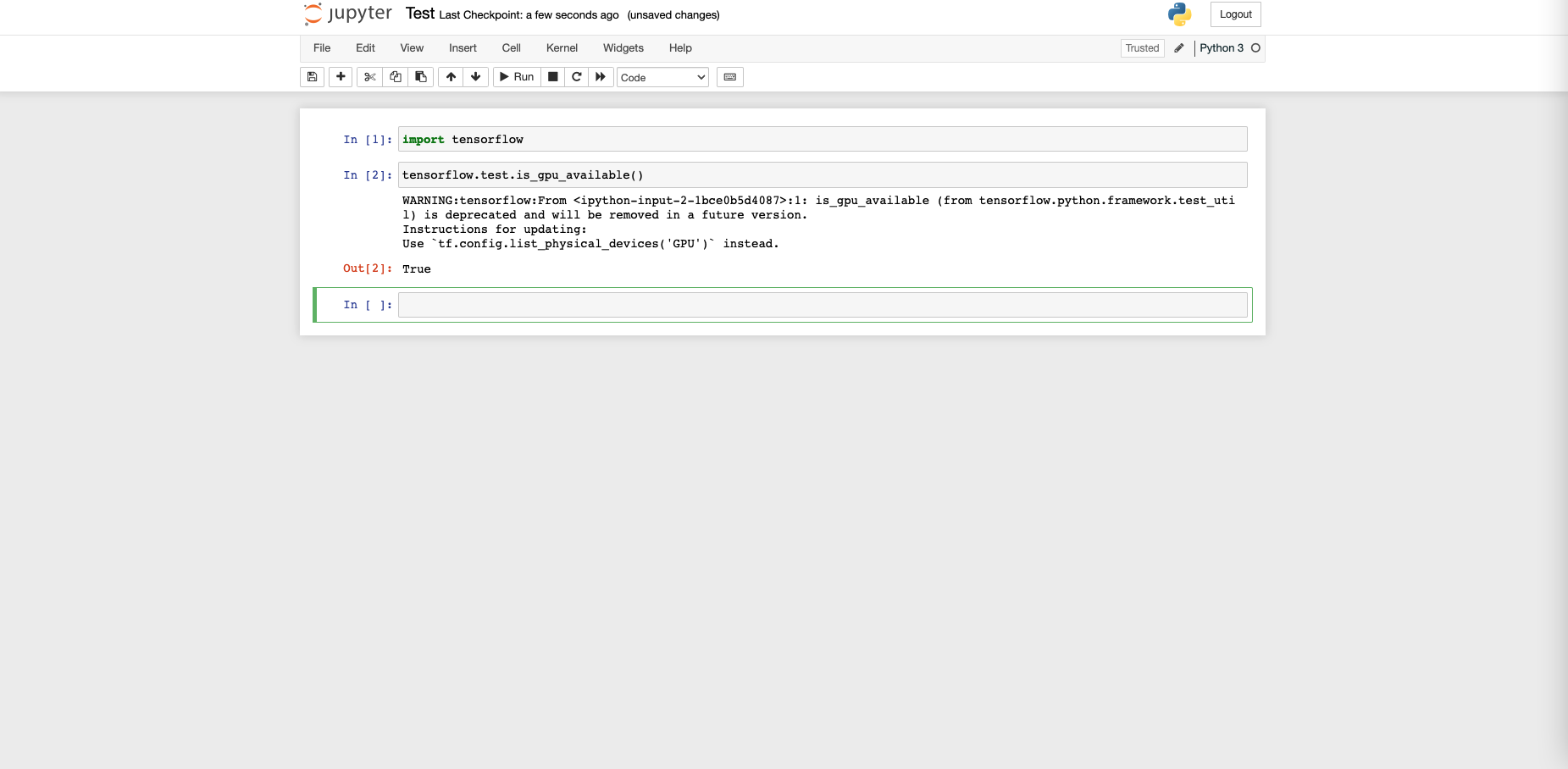
5. 개발 환경 테스트 하기
Jupyter Notebook 에서 TensorFlow 의 FMNIST 예제를 실행시켜 봅니다. 가벼운 데이터셋으로 빠르게 테스트 해볼 수 있는 워크로드이기 때문에 시스템 설정 후 작동시켜보기 좋습니다. 이 때, 동시에 아래 코드를 사용해서 학습 과정에서 GPU 사용률이 얼마나 증가하는지, 정상적으로 사용중인지 체크합니다.
watch -n 0.5 nvidia-smi
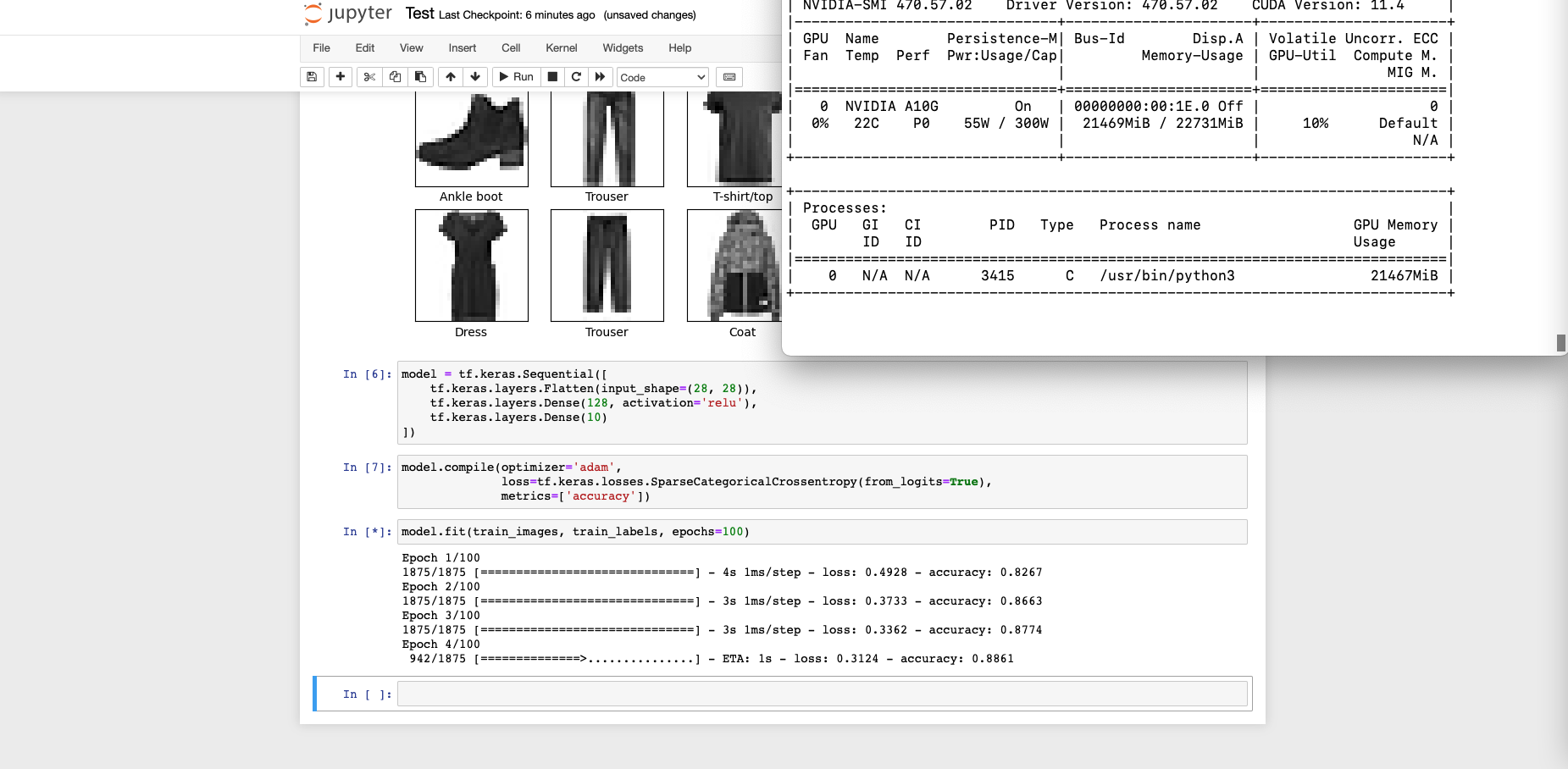
6. 개발 환경 종료하기
GPU 자원은 일반적인 CPU 컴퓨터에 비해 매우 비용이 비싸므로, 작업이 완료되고 더이상 사용이 필요하지 않다면 최대한 빨리 인스턴스를 제거하는 것이 좋습니다. Terminate 를 눌러 인스턴스를 제거하면, 내부의 모든 데이터 등이 제거되므로 주의합니다.
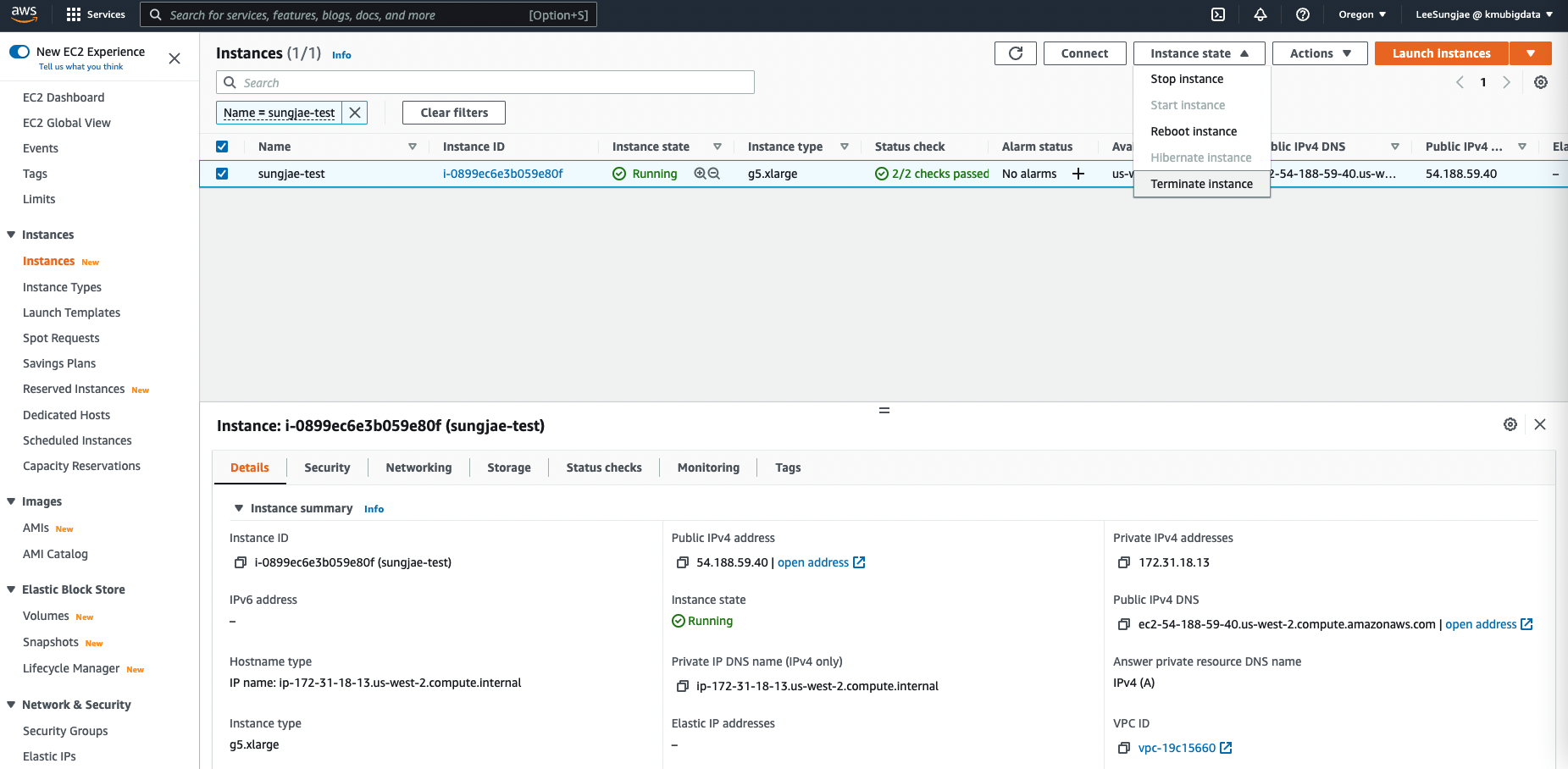
결론
이번 글에서는 AWS 클라우드 환경에서 GPU 자원을 사용하여 딥러닝 학습을 수행하는 방법을 알아보았습니다. 클라우드 환경에는 GPU 자원의 종류만 해도 수십가지가 있으며, 자신의 워크로드의 특성을 잘 파악하고 적절한 GPU 를 선택해야만 작업을 빠르게 수행하고 비용을 절약할 수 있습니다.





