![[kor] Insight of Azure VM Retail Price](/assets/images/wiki/2022-09-29-azure-retail-price/thumbnail.png)
[kor] Insight of Azure VM Retail Price
Azure VM Retail Price데이터로 Spot, Ondemand인스턴스 Price비교
0. 시작하며
비용은 의사결정에 있어 항상 중요한 문제입니다. 대부분의 클라우드 벤더는 spot이라는 다소 저렴하게 유휴 자원을 제공해 VM을 저렴하게 사용할 수 있습니다. 이글에서는 python을 이용해 Azure VM의 spot가격과, ondemand가격을 비교하는 방법에 대해 알아봅니다.
1. Azure란?
- Microsoft에서 운영하는 클라우드 컴퓨팅 서비스입니다. Microsoft 전용 및 타사 소프트웨어 및 시스템을 포함한 다양한 프로그래밍 언어, 도구 및 프레임워크 등 다양한 서비스를 제공합니다.
2. Spot이란?
- Virtual Machine서비스를 사용한 만큼 지불하는 일정한 가격을 Ondemand Price라고 합니다.
- 그러나 Azure Spot Virtual Machine서비스에서는 절감된 비용으로 유휴 인스턴스를 활용할 수 있습니다.
- Spot Virtual Machine을 이용하여 빅데이터 처리, 딥러닝 및 배치 작업과 같은 워크로드를 경제적으로 실행 할 수 있습니다.
- Spot Virtual Machine의 가격은 인스턴스, Region, 시간 등에 따라 달라질 수 있습니다.
이 Spot 가격 데이터를 python으로 API를 이용하여 가격정보를 가져오고 Ondemand가격과 Spot가격을 비교해 보겠습니다.
3. API로 Retail Price 데이터 가져오기
API_LINK = 'https://prices.azure.com:443/api/retail/prices?$filter=serviceName%20eq%20%27Virtual%20Machines%27%20and%20priceType%20eq%20%27Consumption%27%20and%20unitOfMeasure%20eq%20%271%20Hour%27&$skip='
- Azure는 Retail Price를 API로 가져올 수 있습니다.
- 위 API는 VirtualMachines에 대해 1시간동안 사용한 가격에 대한 정보를 가져옵니다.
- Azure Retail Price API는 pagination을 제공합니다.
- 각 API 요청에 대해 최대 100개의 레코드가 반환됩니다.
- 그렇기에 한번에 모든 데이터를 가져올 수 없어 반복문을 이용해 비어있는 데이터가 나올때까지 계속 데이터를 받아옵니다.
4. 모든 페이지의 데이터 가져오기
# 모든 페이지의 데이터를 가져오기위해 0 ~ 200000 까지의 pagination을 이용합니다.
MAX_SKIP = 2000
SKIP_NUM_LIST = [i*100 for i in range(MAX_SKIP)]
# 가져온 데이터는 list로 저장됩니다.
price_data = []
for skip_num in SKIP_NUM_LIST:
# 100, 200, 300... 200000 page까지 데이터를 가져옵니다.
get_link = API_LINK + str(skip_num)
response = requests.get(get_link)
# 만약 상태코드가 200이 아니면 예외를 발생시킵니다.
if response.status_code != 200:
raise Exception(f"api response status code is {response.status_code}")
# list형태로 데이터를 저장합니다.
price_data = list(response.json()['Items'])
# 데이터가 비어있다면 반복문을 종료시킵니다.ㄴ
if not price_data:
break
# list에 추가합니다.
price_list.extend(price_data)
- 0 부터 200000 까지 pagination을 이용하여 RetailPrice를 받아옵니다.
-
그 후 price_list에 price_data를 extend합니다.
- API응답은 다음과 같습니다.
{
'currencyCode': 'USD',
'tierMinimumUnits': 0.0,
'retailPrice': 0.40365,
'unitPrice': 0.40365,
'armRegionName': 'southindia',
'location': 'IN South',
'effectiveStartDate': '2022-05-01T00:00:00Z',
'meterId': '000009d0-057f-5f2b-b7e9-9e26add324a8',
'meterName': 'D14/DS14 Spot',
'productId': 'DZH318Z0BPVW', 'skuId':
'DZH318Z0BPVW/00QZ', 'availabilityId': None,
'productName': 'Virtual Machines D Series Windows',
'skuName': 'D14 Spot',
'serviceName': 'Virtual Machines',
'serviceId': 'DZH313Z7MMC8',
'serviceFamily': 'Compute',
'unitOfMeasure': '1 Hour',
'type': 'Consumption',
'isPrimaryMeterRegion': True,
'armSkuName': 'Standard_D14'
}
- 하지만 json 형식으로는 Spot과 Ondemand를 비교하기 어렵습니다.
- 그래서 pandas의 DataFrame형태로 만듭니다.
5. json데이터 데이터프레임으로 만들기
df = pd.DataFrame(price_list)
- df를 출력하면 다음과 같습니다.
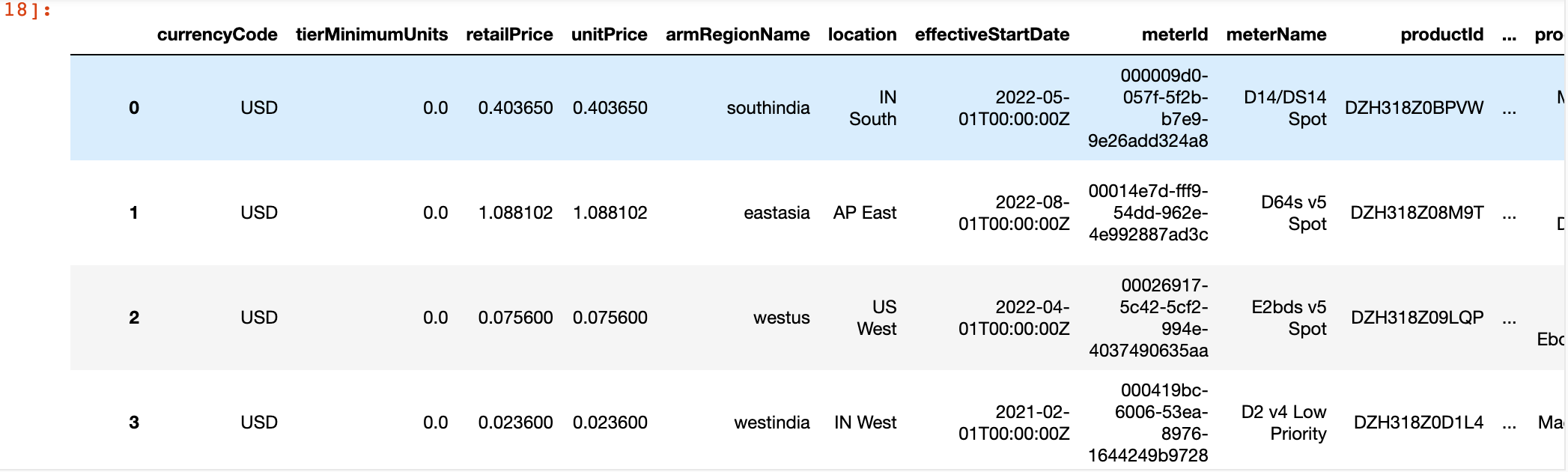
- 139410개의 행과 22개의 열로 이루어진 데이터프레임이 생성되었습니다.
6. 필요한 정보만 가져오기
# Windos를 제외합니다.
df = df[~df['productName'].str.contains('Windows')]
# ‘Low priorty’, ‘Exprired’를 제외합니다.
df = df[~df['meterName'].str.contains('Priority')]
df = df[~df['meterName'].str.contains('Expired')]
#
df = df[df['isPrimaryMeterRegion'] == True]
FILTER_LOCATIONS = ['GOV', 'EUAP', 'ATT', 'SLV', '']
df = df[~df['location'].str.split().str[0].isin(FILTER_LOCATIONS)]
- 현재 response를 그대로 데이터 프레임으로 바꾼 데이터에는 저희가 사용하지 않는게 많습니다.
- 리눅스에 대한 Spot retail price를 사용합니다. Windos는 제외합니다.
- ‘Low priorty’, ‘Exprired’을 포한한 VM 제거합니다.
- Low Priority는 Ondemand보다 다소 저렴한 고정된 가격으로 인스턴스를 제공합니다.
- Expried는 더이상 사용할 수 없는 만료된 인스턴스입니다.
- ‘isPrimaryMeterRegion’는 미터 영역이 기본 미터로 설정되었는지 여부를 나타내고, 기본 미터는 요금 및 청구에 사용됩니다. ondemand일 경우에만 값이 False인 경우가 있었는데, 요금 청구에 사용되지 않는 것이라 True인 경우만 저장하고 Column에서 삭제합니다.
- [‘GOV’, ‘EUAP’, ‘ATT’, ‘SLV’, ‘’]
- 위 리스트에 포한된 location은 spot과 관련이 없기에 삭제합니다.
- 그 결과 41890행까지 줄어들었습니다.
7. 데이터를 ondemand데이터와 spot데이터로 분리

- meterName열은 instanceType이 저장되어 있습니다.
- 하지만 spotPrice가 있는 행에는 instanceType 뒤에 spot이 추가적으로 있고
- ondemandPrice가 있는 행에는 instanceType만 있습니다.
- 이 특징을를 이용하여 instanceTier와 instanceType으로 나누어 줍니다.
# meterName행에 'Spot'이 포함되어 있으면 spot_df, 그렇지 않으면 ondemand_df에 저장됩니다.
ondemand_df = df[~df['meterName'].str.contains('Spot')]
spot_df = df[df['meterName'].str.contains('Spot')]
# meterName을 공백을 기준으로 split해 줍니다. spot이 마지막에 위치함으로 spot을 제외하고 다시 join해 줍니다.
list_meterName = list(spot_df['meterName'].str.split(' ').str[:-1].apply(' '.join))
# 기존 meterName을 삭제하고
spot_df = spot_df.drop(['meterName'], axis=1)
# 새롭게 생성한 meterName을 spot_df에 넣어줍니다.
spot_df['meterName'] = list_meterName
- 그리고 spot_df의 meterName열에서 ‘spot’이라는 정보는 사용하지 않으니 ‘spot’을 제거해 줍니다.
8. 필요한 데이터만 추출.
# spot_df에서 필요한 열만 선택합니다.
spot_df = spot_df[['location', 'armRegionName', 'armSkuName', 'retailPrice', 'meterName', 'effectiveStartDate']]
# ondemand_df의 retailPrice를 ⇒ ondemandPrice로
spot_df.rename(columns={'retailPrice': 'spotPrice'}, inplace=True)
# oddemand_df에서 필요한 열만 선택합니다.
ondemand_df = ondemand_df[['location', 'armRegionName', 'armSkuName', 'retailPrice', 'meterName', 'effectiveStartDate']]
# spot_df 의 retailPrice를 ⇒ spotPrice로 변경해줍니다.
ondemand_df.rename(columns={'retailPrice': 'ondemandPrice'}, inplace=True)
- 사용하지 않는 열을 삭제하고 필요한 열만 남겨둡니다. retailPrice로 저장된 값을 각각 spotPrice, ondemandPrice로 변경해 줍니다.
9. ondemand_df와 spot_df를 join
# 'location', 'armRegionName', 'armSkuName', 'meterName'를 이용하여 outer join을 합니다.
join_df = pd.merge(ondemand_df, spot_df,
left_on=['location', 'armRegionName', 'armSkuName', 'meterName'],
right_on=['location', 'armRegionName', 'armSkuName', 'meterName'],
how='outer')
-
ondemand_df와 spot_df를 join해 줍니다.
-
join한 결과는 다음과 같습니다.
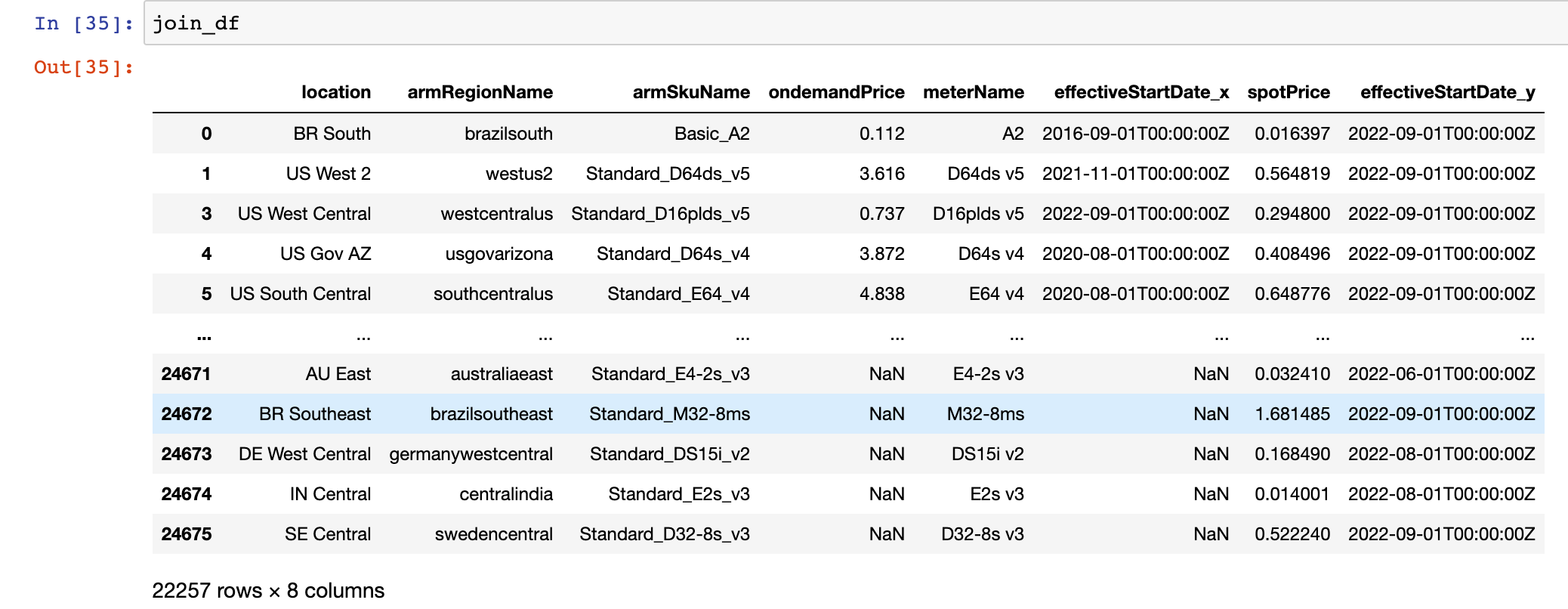
22257개의 행, 8개의 열입니다.
10. Savings계산
join_df.loc[join_df['ondemandPrice'] == 0, 'ondemandPrice'] = None
join_df['savings'] = (join_df['ondemandPrice'] - join_df['spotPrice']) / join_df['ondemandPrice'] * 100
- savings를 계산해줍니다.
- (ondemandPrice - spotPrice) / ondemandPrice * 100 식으로 계산하여 savings열에 저장해 줍니다.
- spotPrice가 ondemandPrice에 비해 몇 %저렴한지 보여줍니다.
11. InstanceTier, InstanceType 분리
# get instancetier from armSkuName
def get_instaceTier(armSkuName):
split_armSkuName = armSkuName.split('_')
# 만일 빈 데이터였다면 nan값으로 리턴
if len(split_armSkuName) == 0:
instaceTier = np.nan
return instaceTier
#InstanceTier가 존재한다면 리턴, 아니라면 nan리턴
if split_armSkuName[0] == 'Standard' or split_armSkuName[0] == 'Basic':
instanceTier = split_armSkuName[0]
else:
instanceTier = np.nan
return instanceTier
# get instancetype from armSkuName
def get_instaceType(armSkuName):
split_armSkuName = armSkuName.split('_')
# 만일 빈 데이터였다면 nan값으로 리턴
if len(split_armSkuName) == 0:
instaceType = np.nan
return instaceType
#InstanceTier만 존재한다면 nan리턴 아니라면 IstanceType리턴
if split_armSkuName[0] == 'Standard' or split_armSkuName[0] == 'Basic':
if len(split_armSkuName) == 1:
instanceType = np.nan
return instanceType
instanceType = '_'.join(split_armSkuName[1:])
else:
instanceType = split_armSkuName[0]
return instanceType
------------------------------------------------------------------------------------------
join_df['instanceTier'] = join_df['armSkuName'].apply(lambda armSkuName: get_instaceTier(armSkuName))
join_df['instanceType'] = join_df['armSkuName'].apply(lambda armSkuName: get_instaceType(armSkuName))
- armSkuName열에는 ‘InstanceTier_IntanceType’의 형태로 데이터가 한 열에 저장되어 있습니다.
- 이를 별도의 InstanceTier, InstanceType열로 나눈어줍니다.
join_df = join_df.reindex(columns=['instanceTier', 'instanceType', 'location', 'ondemandPrice', 'spotPrice', 'savings'])
join_df.rename(columns={'location': 'region'}, inplace=True)
- 열의 순서를 다시 정렬해주고 location열의 이름을 region으로 바꾸어 줍니다.
12. 결과
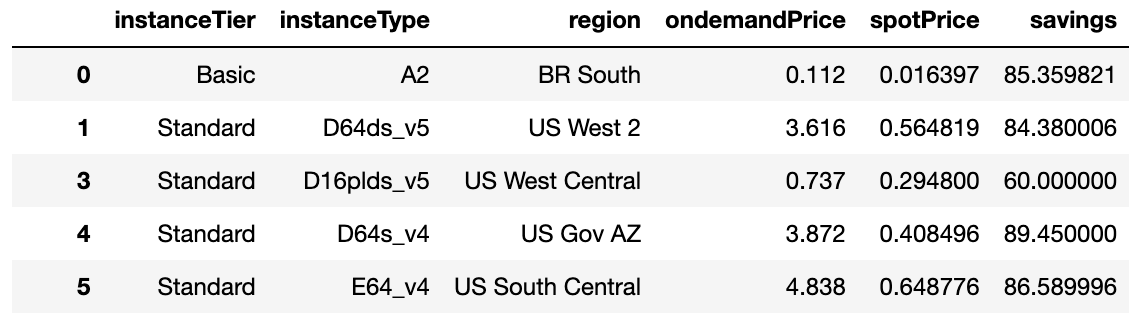
- 각 리전별 intnaceTier, instanceType에 따른 ondemandPrice와 spotPrice 그리고 spot이 ondemand에 비해 얼만큼 저렴한지를 %로 나타내는 savings로 DataFrame을 완서하였습니다.
- 모든 Price는 USD입니다.
13. 결론
- 이렇드 각 리전, 인스턴스에 대한 온디맨드, 스팟, 그리고 saving를 계산해 df로 표시하였습니다.
- 이 데이터를 주기적으로 저장하고 분석한다면 다양한 워크로드를 Azure Virtual Machine에서 실행한다면 가격을 최적화 할 수 있습니다.
- 또한 spot가격을 모니터링 하면서 인스턴스가 중단되지 않고 계속 가용성을 유지하도록 할 수 있습니다.
14. 참고
- https://learn.microsoft.com/ko-kr/rest/api/cost-management/retail-prices/azure-retail-prices
- https://en.wikipedia.org/wiki/Microsoft_Azure
- https://azure.microsoft.com/ko-kr/products/virtual-machines/spot/#overview
- Sungjae Lee, Kyungyong Lee / Empirical Analysis and Offering of Various Historical Spot Instance Datasets





