![[kor] How to use TensorBoard in EC2](/assets/images/wiki/2022-09-22-tensorboard-in-ec2/thumbnail.png)
[kor] How to use TensorBoard in EC2
0. Intro
클라우드 환경에서 딥러닝 학습작업 혹은 추론 작업시 프로파일링을 통해 어떤 과정이 어떻게 진행되었는지 자세히 분석할 수 있습니다. 이 글에서는 TensorBoard를 활용한 프로파일링 방법에 대해 알아봅니다.
TensorBoard란 ?
TensorBoard는 TensorFlow 에서 발생한 로그를 표시하거나 디버깅을 하기 위한 도구로 그래프를 그려 통계를 시각화해주는 것이 주요 기능입니다.
1. Basic Usage
딥러닝 모델 사용시 TensorBoard 코드 예시
딥러닝 모델로 학습을 하는지, 추론을 하는지에 따라 TensorBoard를 활용하는 코드가 달라지게됩니다.
-
딥러닝 학습시 TensorBoard 코드 사용법
# 로그가 저장될 디렉토리를 설정합니다. logs = "./logdir" # 필요한 callback 함수를 정의합니다. tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs, histogram_freq = 1, profile_batch = '1,2') # 모델 학습시 callback 함수를 호출하도록 설정합니다. model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), callbacks = [tboard_callback])- Callback 함수는 모델 학습 중 호출할 수 있는 기능을 의미합니다.
- tf.keras.callbacks에는 일반적으로 사용할 수 있는 함수가 구현되어있고 직접 필요한 기능을 구현해서 사용할 수도 있습니다.
- tf.keras.callbacks.TensorBoard
-
histogram_freq 는 모델 레이어에 대한 활성화 히스토그램을 계산할 빈도를 의미합니다.
1로 설정하는 경우 히스토그램이 계산되며 0으로 설정한다면 히스토그램이 계산되지 않습니다.
-
profile_batch 는 음이 아닌 정수 튜플이어야하며 양의 정수 쌍은 프로파일링할 batch 처리 범위를 나타냅니다.
-
-
딥러닝 추론시 TensorBoard 코드 사용법
predict function에 callback 함수를 넣으면 제대로 프로파일링이 진행되지 않습니다.
따라서 tf.profiler API를 사용해서 추론 과정을 프로파일링해야합니다.
model.predict 함수의 앞 뒤로 tf.profiler API를 추가하여 프로파일링을 진행합니다.
# 로그가 저장될 폴더명'logdir'을 파라미터로 입력합니다. tf.profiler.experimental.start('logdir') yhat = model.predict(batch) tf.profiler.experimental.stop()
2. EC2에서 TensorBoard 사용법
- EC2 인스턴스 생성하기
-
먼저 AWS Console 환경에서 EC2를 서비스를 선택 후 인스턴스를 생성합니다.
( EC2의 자세한 생성 과정은 “[kor] GPU Enabled Jupyter Notebook Settings on AWS EC2” 글의 일부 참고 ** )
-
- 보안 그룹 설정하기
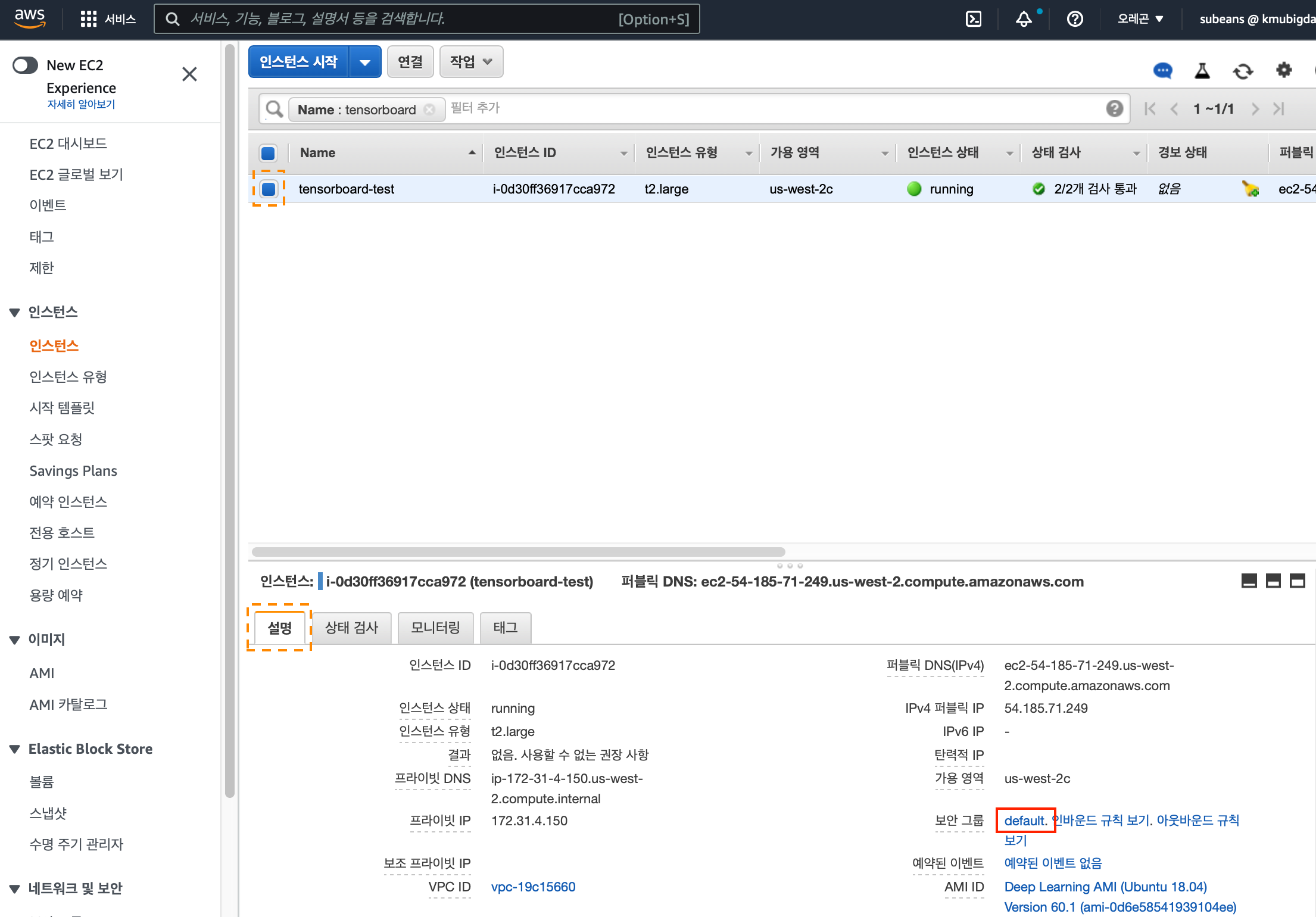
- 인스턴스 생성 후 인스턴스 체크박스를 선택하면 하단의 설명 탭을 확인할 수 있습니다.
-
설명탭의 내용 중 인스턴스 생성시 설정한 “보안그룹 이름”을 선택합니다.
-
-
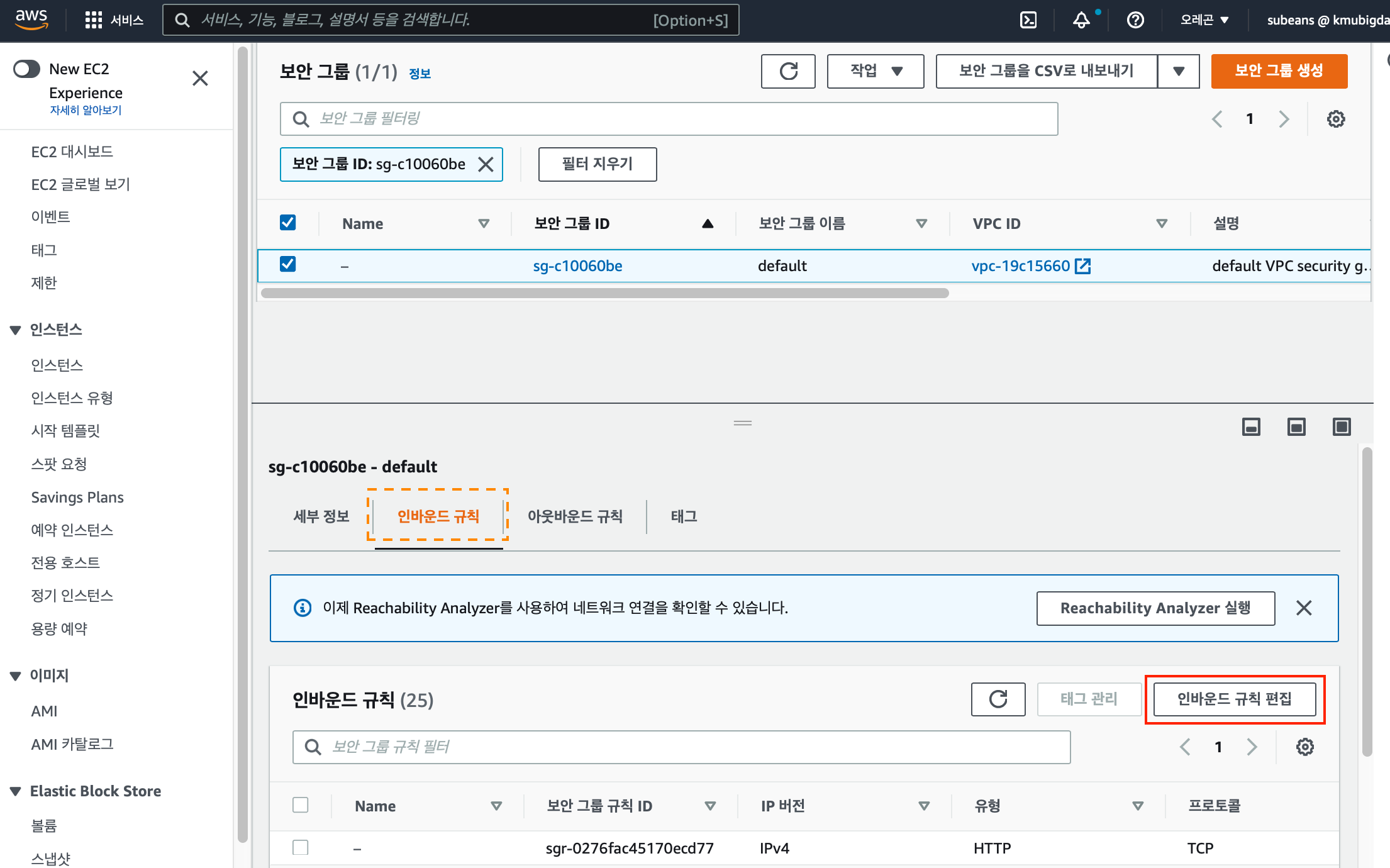
보안그룹 화면에서 하단의 “인바운드 규칙”을 선택하고 “인바운드 규칙 편집”을 클릭합니다.
-
왼쪽 하단의 “규칙 추가” 버튼을 누른 후 포트범위 6006을 설정하고 소스는 Anywhere-IPv4로 설정합니다.
오른쪽 하단의 “규칙 저장”을 눌러 인바운드 규칙을 저장합니다.
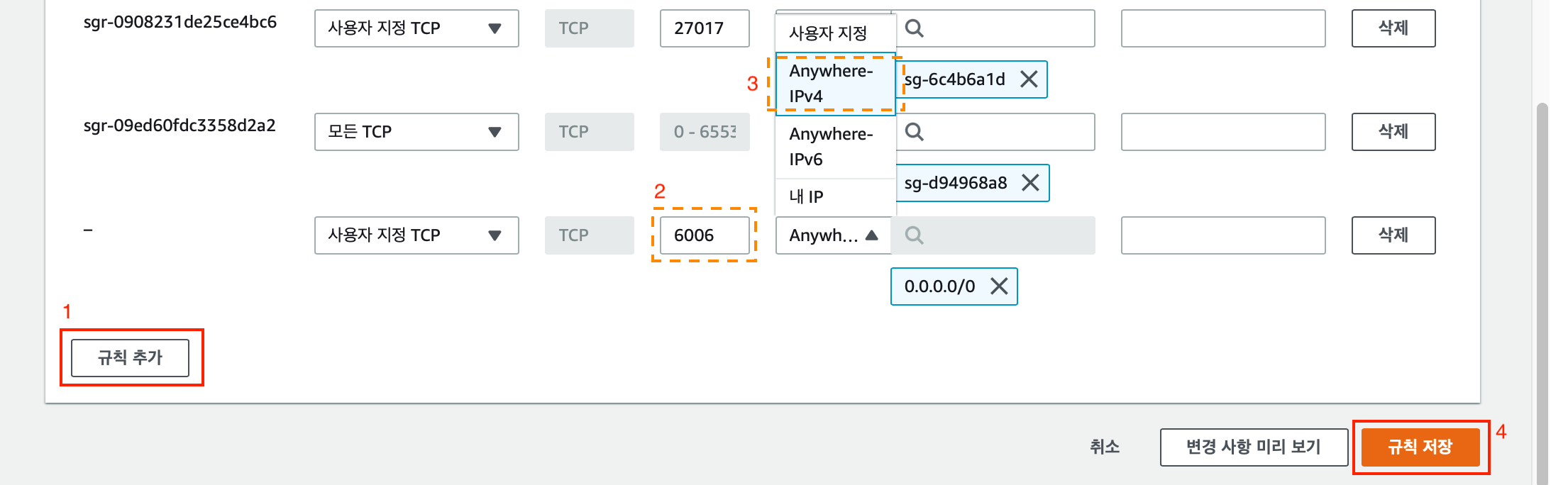
- 인바운드 규칙 목록에 6006 포트 규칙이 생성되었음을 확인합니다.
- 인스턴스 생성 후 인스턴스 체크박스를 선택하면 하단의 설명 탭을 확인할 수 있습니다.
- TensorBoard를 위한 로그 저장하기
- 인스턴스에 접속 후, 딥러닝 학습 또는 추론 중 필요한 작업을 실행합니다.
- 실행 후 logdir 이 생겼음을 확인합니다.
ubuntu@ip-172-31-4-150:~/cloud-inference$ ls inference.py **logdir** resnet50 save_model.py
- 인스턴스에 접속 후, 딥러닝 학습 또는 추론 중 필요한 작업을 실행합니다.
- TensorBoard 실행하기
-
먼저 필요한 tensorboard-plugin-profile을 설치합니다.
pip3 install -U tensorboard-plugin-profile -
tensorboard 실행
tensorboard --bind_all --logdir=./logdir- SSH 접속을 통해 ec2 에서 tensorboard를 실행하고 로컬에서 tensorboard창을 띄우게될 경우
—bind_all파라미터를 입력해야합니다. -
그 다음 로컬환경에서 Chrome에 접속하고, 아래와 같은 주소 형식으로 접속합니다.
http://PublicDNS:6006
http://ec2-xx-xxx-xxx-xxx.us-west-2.compute.amazonaws.com:6006/
-
EC2 보안그룹에서 6006 포트를 열어주었기 때문에 6006으로 접속해야합니다.
따라서 6006 port 가 이미 사용중이라면 포트를 닫고 다시 실행합니다.
# 6006 포트를 사용하고 있는 PID 를 확인합니다. lsof -i:6006 # 6006 포트를 사용하고 있는 PID 를 입력해 종료합니다. kill -9 *PID*
- SSH 접속을 통해 ec2 에서 tensorboard를 실행하고 로컬에서 tensorboard창을 띄우게될 경우
-
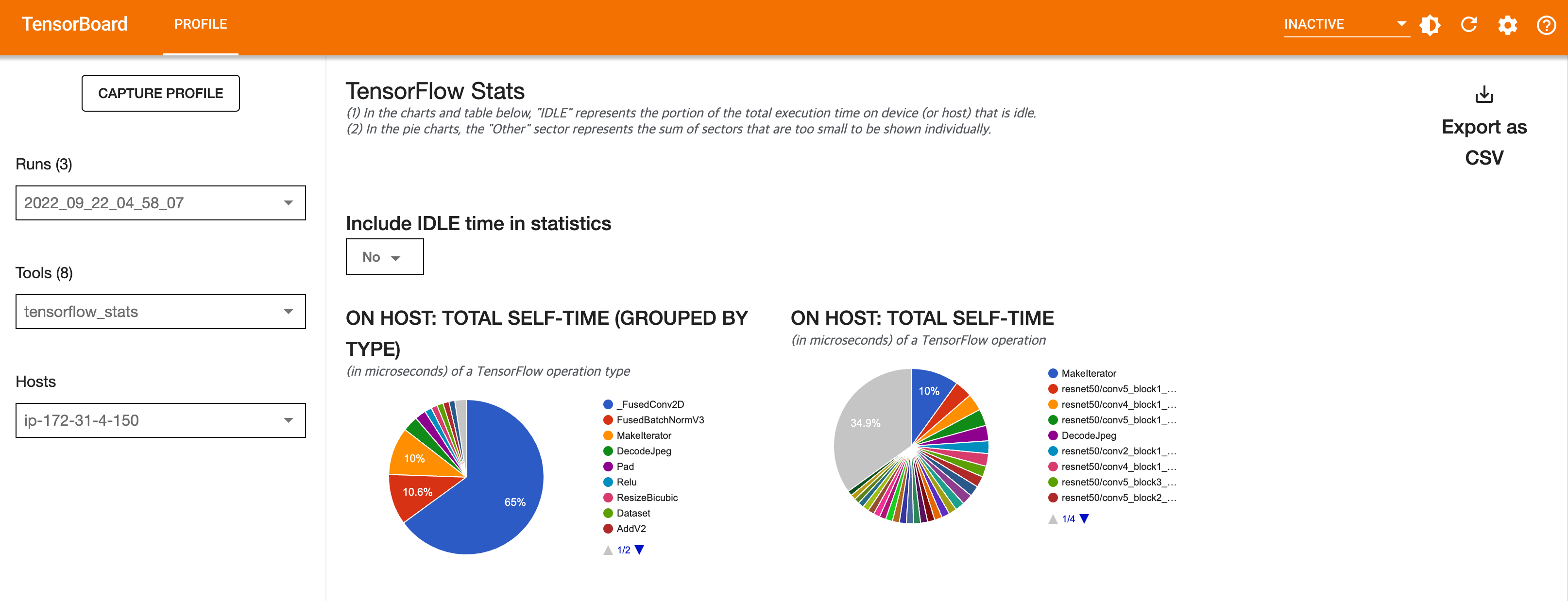
상단의 PROFILE 탭에서 프로파일링 결과를 확인할 수 있습니다.
-
Reference
https://ddps.cloud/Wiki-kor-GPU-Enabled-Jupyter-Notebook-on-AWS-EC2
https://docs.aws.amazon.com/ko_kr/dlami/latest/devguide/tutorial-tensorboard.html
https://www.tensorflow.org/api_docs/python/tf/profiler
https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TensorBoard





